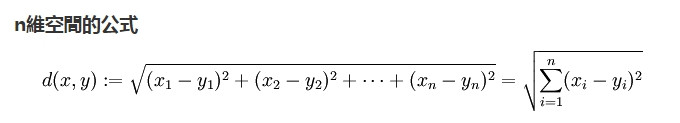
接續前言
先複習一下
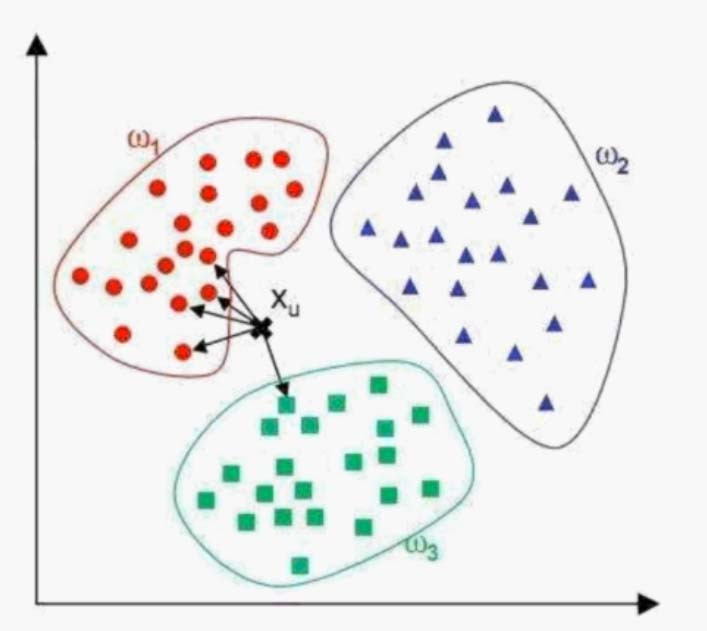
現有的三類訓練集數據,有一個新的樣本Xu,選取了距離最近的(預設參數設定k=5)個點
KNN算法偽代碼
假設X_test為待標記的數據樣本,X_train為已標記的數據集,偽代碼如下:
遍歷X_train中的所有樣本,計算每個樣本與X_test的距離,並把距離保存在Distance數組中
對Distance數組進行排定,取距離最近的k個點,記為X_knn
在X_knn中統計每個類別的個數,即class_0在X_knn中有幾個樣本,class_1在X_knn中有幾個樣本
待標記樣本的類別,就是在X_knn中樣本個數最多的那個類別
算法參數
算法參數: k
一般k的取值為1-20
當k=1時,為最近鄰算法
Sklearn中,K默認為5
距離一般用歐式距離或者曼哈頓距離
歐式距離公式: